



![[Img #74870]](https://thelatestnews.world/wp-content/uploads/2025/01/Artificial-Intelligence-and-false-data-in-biomedicine-150x150.jpg)






Every day we look for tons of information on the Internet. Sometimes the results are not what we are looking for and sometimes quite the opposite. But how does the internet know what we want? The answer is a Search Engine.
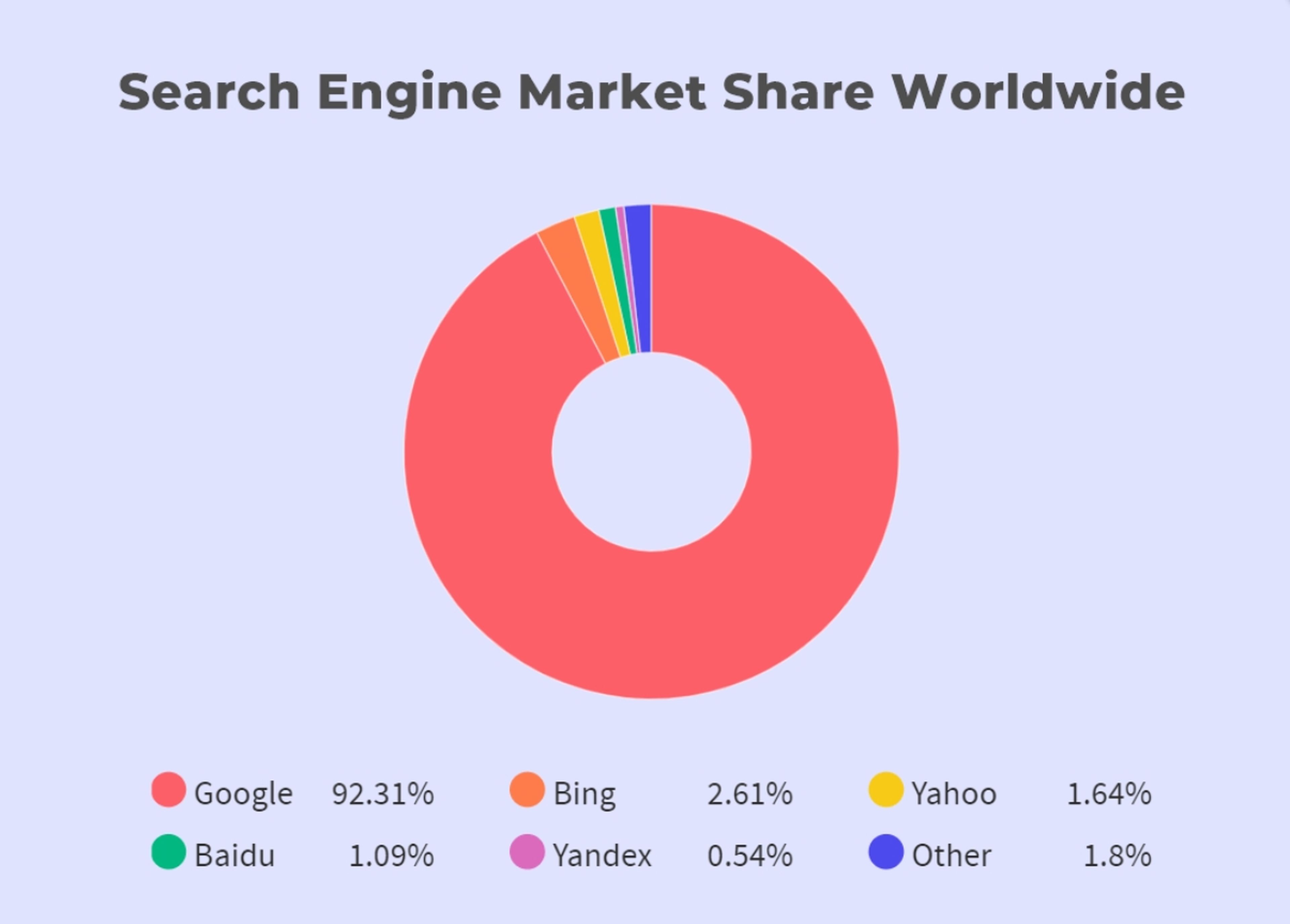
Surely words like Google, Bing, Yahoo, etc. sound familiar to you. All of them are search engines that select the best results for the queries that we enter. That is why, Given its broad utility, we want to go deeper to understand what a search engine is.
There is no best search engine. Although the Google algorithm is superior to the others, that does not mean that it will always offer the best results. Several search engines are fighting to enter the category of the most popular, such as the much-known DuckDuckGo.
With all this we are base, let’s enter the world of search engines, explained in a very simple way and of course, let’s see the difference with the concept of browser web because Google and Google Chrome are not the same.
What is a search engine?
A search engine is a computer program that is accessed through the Internet and that searches a database of information according to the user’s query. The web browser, with which this concept is often confused, provides a list of results that best match what you want to find.
Today there are many different search engines in Internet, each with its own capabilities and characteristics. The first developed search engine is considered to be Archie, which was used to search for FTP files, and the first text-based search engine is considered to be Veronica. Currently, the best known and used search engine is Google.
How search engines work
Search engines may differ from one another in the way they provide answers to the user, but all of them They are based on the 3 fundamental principles:
- Tracking
- Indexing
- Classification
1. Crawling: The discovery of new web pages on the Internet begins with the process called crawling.
Search engines use small programs called crawlers. Web (sometimes called bots or spiderbots) that follow links from familiar pages to new ones to discover.
Whenever a spiderbot finds a new web page via a link, it scans and passes its content for further processing (called indexing) and continues to discover new web pages.

2. Indexing: Once the data is crawled by the robots, it is time for indexing: the process of validating and storing the content of the web pages in the search engine’s database called an “index”. It’s basically one big library of all the websites.
Your website has to be indexed to appear on the search engine results page. Keep in mind that both crawling and indexing are continuous processes that take place over and over again to keep the database up to date.
Once the web page is parsed and saved to the index, can be used as a search result for a potential search query.
3. Ranking: The last step is to select the best results and create a list of pages that will appear on the results page. Every search engine uses dozens of ranking signals and most of them are kept secret, not available to the public.
How do search engines rank results?
A single search can return billions of relevant web pages, so Part of a search engine’s job is to sort these listings using ranking algorithms.
And while these algorithms are designed to give you the best answers to your questions, they are biased towards certain factors. Search engines want to show you results that you click on, and they use a number of factors to rank the results based on what they think will interest you. These factors are, among others:
1. Use of keywords. The search results must match at least some of the words in the query. Search engines give priority to pages where those keywords appear prominently, such as the page title, or often the entire page.
2. Content of the page. Search engines prioritize high-quality content by analyzing the length, depth, and breadth of web pages.
3. Backlinks. Backlinks, or mentions of one website on another, can be considered a vote in favor of that site’s authority. Backlink ranking, promoted by Google PageRank, ranks pages based on the number of websites linking to that site and the position they occupy in the ranking.
4. User Information. Search engines like Google use your personal information, such as search history and location, to deliver results that are relevant to you.

Difference Between Search Engine and Web Browser
Many people still think that browsers and search engines are the same thing. Although they work together, there are differences between them. So let’s delve into the world of web browsers. versus search engines.
The search engine we have already explained, so let’s get into the web browsers. Web browser is an example of application software that is developed to retrieve and view information from web pages or HTML files present on web servers.
| Search Engine | Web navigator | |
|---|---|---|
| Definition | A search engine is used to find information on the World Wide Web and displays the results in one place by returning the web pages available on the Internet. | The web browser uses the search engine to retrieve and display the information of the web pages present on the web servers. |
| Use | Search engines are designed to collect information about various URLs and maintain it. | Web browsers are designed to display the current URL web page available on the server. |
| Facility | The search engine does not need to be installed on our system (ie it comes by default). | Many Web Browsers can be installed on our system. |
| Components | The indexer, crawler, and database are the three essential components of a search engine. | A web browser uses a graphical user interface to help users have an online session on the Internet. |
| Database | A search engine contains its own database. | The web browser does not need any database. It only contains cache memory to store cookies as well as browsing history until we remove it from our system. |
| Dependence | You don’t need a search engine to open the browser. This means that the search engine depends on the browser. | A browser is needed to open a search engine. This means that the browser does not depend on the search engine. |
| Advantages | The top advantages of search engines are consumer trust, trackable results, targeted traffic generation, sustainable clicks, and growing your small business. | The main advantages of using a web browser are open standards, security sandbox, robust graphical user interface, and easy networking. |
| Disadvantages | The disadvantages of using search engines are keyword difficulty, changing algorithms, and unguaranteed results. | The disadvantages of using web browsers are slowness and the possible lack of added support. |
| examples | Google, Yahoo, Bing, DuckDuckgo, Baidu, Internet Explorer. | Mozilla Firefox, Netscape Navigator, or Google Chrome. |
The first browser was invented by Sir Tim Berners-Lee in 1990. and the first graphical browser was developed in 1993 under the name of Mosaic. Several web browsers were later developed. Some of them are Navigator, developed by Netscape Communication, Microsoft Edge, Google Chrome, Mozilla Firefox, Opera and Apple Safari.
Examples and types of search engines

The search engines we all know like Google may be the first to come to mind when we think of search engines, but there are other types of search engines that allow us to navigate the Internet.
On the one hand we have the conventional search engines, in which we find Google (and its addition of IA Bard), Bing and Yahoo, which are free and are financed by online advertising. They all use variations of the same strategy (crawling, indexing and sorting) to allow you to search the entire Internet.
On the other hand, there are private search engines. These have recently gained popularity due to privacy concerns about the data collection practices of mainstream search engines. These include advertising-supported anonymous search engines like DuckDuckGo and ad-free private search engines like Neeva.

We also highlight the vertical search engines. And it is that, the vertical search, or specialized, is a way of limiting the search to a thematic category, instead of the entire web.
Some examples of vertical search engines are: the search bar on shopping sites like eBay and Amazon, Google Scholar, which indexes scholarly literature through journals, or social media search sites and apps like Pinterest.
We end with the fourth type, the computational search engines. WolframAlpha is an example of a computational search engine, dedicated to answering questions related to mathematics and science.
Well, now that you have a more or less general idea of this whole wide world, It only remains to say that, taking into account your interests, choose the search engine that best suits you. to what you wantBecause as you can see, there are options for all tastes.
![[Img #74870]](https://thelatestnews.world/wp-content/uploads/2025/01/Artificial-Intelligence-and-false-data-in-biomedicine-300x200.jpg)

