








Microsoft’s plan to implement ChatGPT within its core solutions is still ongoing. It will arrive at Bing in the first quarter of this year, and there is already information about upcoming implementations within the Office suite. But ChatGPT is not alone, Microsoft has a new ace up its sleeve.
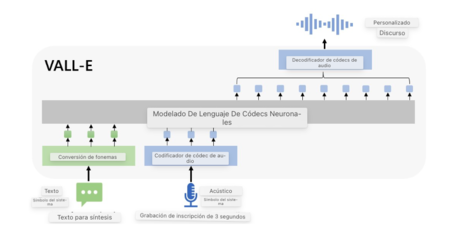
His name is VALLEY, and it is a language model for text-to-speech synthesis (TTS). Microsoft promises that you only need three seconds of audio recording for the system to be able to imitate your voice.
Microsoft wants artificial intelligence in everything

Microsoft has a new text-to-speech model that is capable of imitating any voice with a recording of just three seconds. One of the most interesting points that the company shares in its documentation is that they are developing VALL-E to work with other generative AI models, such as GPT-3.
In other words, ChatGPT itself would be able to offer us voice results once this model is integrated. An “imitate the voice of chiquito de la calzada” would be possible, as long as the necessary prior training has been carried out for it.

The examples that Microsoft shows are simply spectacular. In them, he shows us what has been the audio input that has been taken as a base, the intermediate steps and the final result of VALL-E. The model is not only able to imitate the voice, but the original cadence of language itself and the original pitch with which the voice input was recorded.
This is not something especially new, and it is that Google already boasted of similar models years ago. However, the applications of Google’s most powerful AIs in popular solutions are not as present as Microsoft plans. We will have artificial intelligence in the browser, in the office automation apps and, as they detail now, this AI will also be voice.


![[Img #74661]](https://thelatestnews.world/wp-content/uploads/2024/12/The-power-of-ultrasound-300x200.jpg)