








Where we come from, AMD XDNA
AMD designed XDNA with the same goal as AMD XDNA2that is, saving energy in applications based on typical operations of data models for artificial intelligence. The objective has always been to have a parallel calculation model, with easy programming, capable of saving energy in these processes. Without a doubt, it is aimed at processors in environments where consumption is an important factor, not only for autonomy but also for heat management.
Initially focused on processors for laptops or the increasingly popular MiniPC formats, they have ended up also reaching processors more oriented to desktop systems, always in the same combination of SOC with powerful CPU, high-performance GPU and NPU for offloading AI operations.
In technical terms, AMD XDNA incorporates a field-programmable gate array (FPGA) architecture, which allows for dynamic hardware reconfiguration to adapt to different workloads. This real-time reprogrammability offers unprecedented flexibility, allowing developers to optimize performance for specific applications, from artificial intelligence and machine learning to data processing and advanced graphics.
Additionally, AMD XDNA utilizes advanced power management techniques, integrating multiple levels of voltage and frequency control to adjust power consumption based on workload. This not only improves energy efficiency, but also extends hardware lifespan by reducing thermal and electrical stress.
Another notable technical feature is the integration of specific accelerators within the XDNA architecture, which are designed for computationally intensive tasks. These accelerators can include graphics processing units (GPUs), artificial intelligence (AI) processing units, and other specialized components that work together to deliver superior performance.
In short, AMD XDNA technology combines configurability, power efficiency, and targeted acceleration to deliver a highly adaptable and powerful processing solution suitable for a wide range of modern technology applications.
NPU with efficiency as its cornerstone
It is certainly quite a surprise that AMD’s “Strix Point” SOCs appear to be its most complex CPUs, with more hardware input than, for example, the new Ryzen 9000 desktop processors. This has a clear explanation: the aim is to achieve efficiency in each task that the processor executes, including those related to local AI.
A desktop CPU has more power, more performance cores, a higher working frequency and also a large number of instructions usually related to AI and in the vast majority of cases a GPU that today is much more powerful in these tasks, but not more efficient. A good example is the Radeon 7900 GRE, a great card for gaming, which also produces 92TOPS of processing power in FP16 models, or a GeForce RTX 4070 Super that triples this power reaching 284 TOPS in the same data model.

In short, on a computer with a mid-range or high-end GPU we will always have more processing power for AI, but we will be much less efficient. In fact, AMD has measured this efficiency by comparing its processors with NPU, without NPU and with a dedicated GPU and in the appropriate operations its new second-generation NPU, based on XDNA2, is 35% more efficient than classic CPU functions when the GPU is only 8% more efficient. The key is not only the processing speed, but also the energy consumption and freeing up the less efficient areas of the processor from a task for which they are not specialized.
Keys to the architecture of the new NPU based on XDNA2
This generation of AI accelerator integrated into AMD’s new Ryzen AI brings significant improvements focused not only on the new capabilities needed to add processing power but also to be much more efficient in its executionThe key is to save energy in laptop designs that are increasingly demanding in terms of size, performance and autonomy.

AMD’s NPU is structured in a tile design that is more efficient in memory management, with less access and management by software, and also more efficient use of the cache. The design allows for completely flexible partitioning both in designs where the pool of operations is managed linearly, executing one operation after another, or dividing the NPU into sections capable of executing different operations completely in parallel.
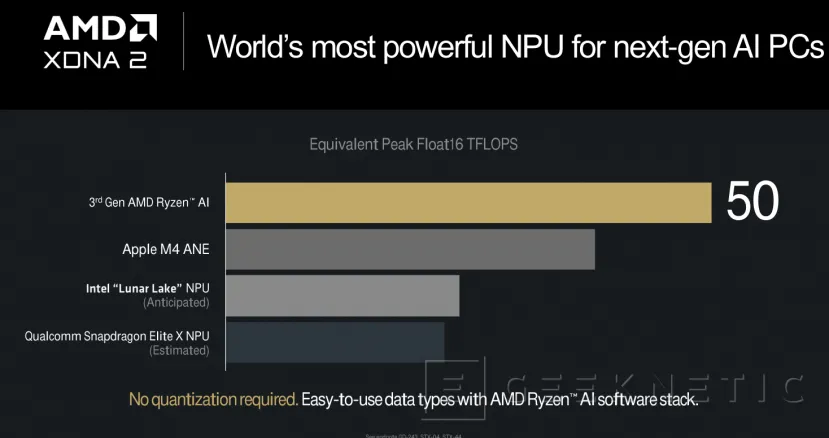
This generation adds 12 new tiles on top of the previous designfor a total of 32, but manages to increase performance by five units, going from 10 TOPs to no less than 50 TOPs (Teraflops per second).

This new design is not only significantly faster, achieving the fastest NPU integrated into a processor for portable home environments, but is also twice as energy efficient as the previous generation.
The importance of the data model, AMD introduces the FP16 Block in its new NPUs
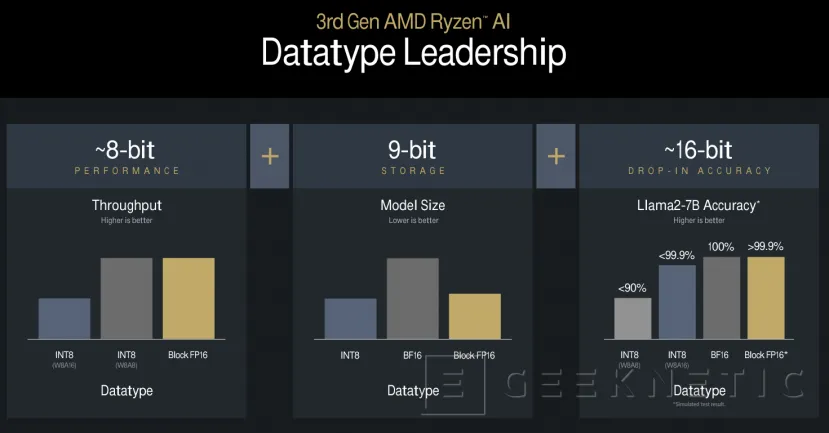
Currently, almost all AI applications use data models based on 16-bit precision, which is obviously more demanding than 8-bit precision. AMD has introduced a new model capable of generating precision close to 16-bit precision with the processing demands of 8-bit precision, and They have called it Block Floating Point or Block FP16.

The most characteristic models can now be trained with this new AMD technology and in fact some, such as the Llama2-7B, are capable of producing performances close to 8-Bit with precisions greater than 99.9% compared to those generated natively in FP16. The performance is superior, practically double, with the additional advantage that they take up less space, significantly less, than those trained with FP16 models.
AMD is not only introducing new, more efficient data models, but is also working with the main players in this revolution and not only with private entities, such as Microsoft within its Copilot+ initiative for Windows 11 certified computers with AI, but also on completely open standards so that anyone can use and take advantage of these new technologies in a completely transparent way and with an open source license.
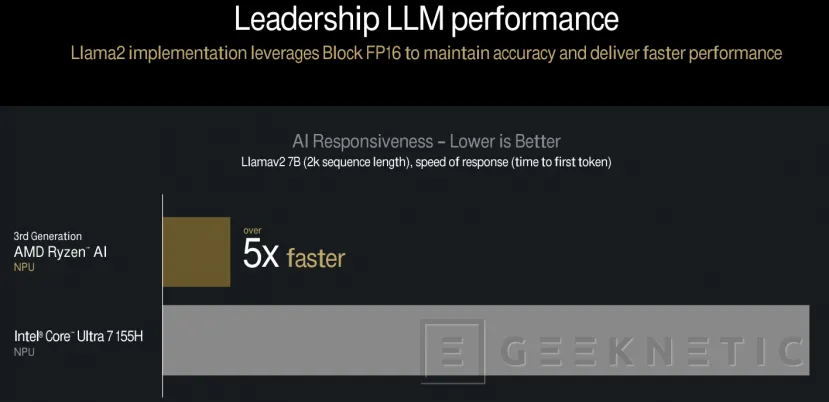
Currently, the new third-generation Ryzen AI, which we have talked about in this other article, can even be used with its Block FP16 model, in widely used models such as “Stable Diffusion XL Turbo”, or also in its implementation in “Llama2-7B” with up to five times more performance than the NPU integrated in the Intel Core Ultra 7 155H.
Advantages of a “local” NPU
Although it is clear that the AI revolution for home use comes from the implementation of big data models based on the cloud, the contribution of local processing also has its advantages and In fact, the feeling of hardware manufacturers is that we are going towards a hybrid AI model..

Part of the workload is local for two fundamental reasons: to reduce the cost of data centers, something that is undoubtedly on the minds of the main players, and secondly, for security reasons, we can keep our information safe in our personal or professional environment.
I have no doubt, especially when fully standardized models are available in widely used APIs such as DirectX or Vulkan, that these AI techniques will also be applied to cutting-edge games, as is already being done in many content creation applications, in filter or post-processing mode, where these types of techniques achieve exceptional results without the need to run the processing loads in the cloud.
Combined with a SOC for a complete solution
Although we are sure that in the coming weeks or months this technology will reach desktop environments, normally in some AMD Ryzen 9000 G-series processor with integrated RDNA 3.5 graphics, the truth is that this technology is currently limited to processor models AMD Ryzen AI 365 and AMD Ryzen AI HX 370 that we will see in new generation ultralight laptops.
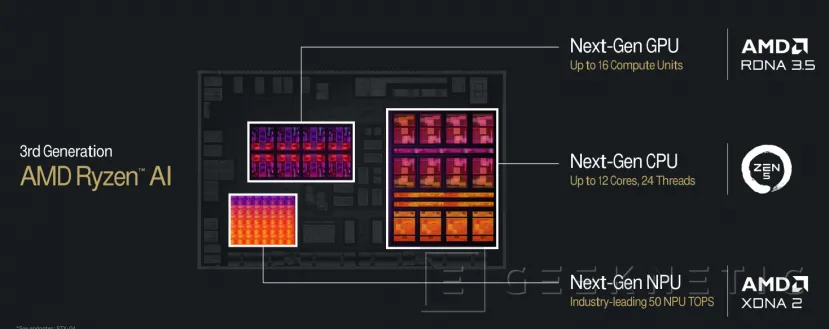
These processors, included in the SOC codenamed “Strix Point,” seek efficiency in the execution of all types of modern tasks. On the one hand, balancing games, computing and graphics towards a powerful GPU that has evolved in this generation precisely to be more efficient in the use of memory and consumption and also with a new NPU that is more powerful and efficient in the use of energy.
Sa also supports in New Zen5 and Zen5c cores low consumption for the most common tasks. A careful combination where AMD wants to present a powerful processor that is versatile, fast and powerful, but above all careful with the use of energy and the need for cooling, which allows laptop models with greater autonomy and more elegant and stylized designs.
In this sense the NPU AMD XDNA2 It seeks nothing other than to contribute this same idea to the local process of artificial intelligence models on a unified basis that supports all current technologies in a unified way.
End of Article. Tell us something in the Comments!

Add Comment